
After completing his secondary education with university entrance qualification, Paul, a french student, is quickly confronted with many questions:
- Which university/preparatory class to choose?
- Where finding a not too expensive housing?
- Where finding a summer job?
- Where drinking in a nice place in Paris?
- Which doctor is the closest to my home?
- I go to London to study. What are the cheapest aircraft tickets?
- …
Web? App? Bot?
Web is an information source for Paul but informations are not presented according to its constraints (e.g. location, budget …). The principle There is an app for That obliges him to download an app for each of its above questions (e.g. Yelp, Skyscanner …). But, Paul is left with a multitude of applications on their smartphone even sometimes requiring juggling from one to the other.
![]()
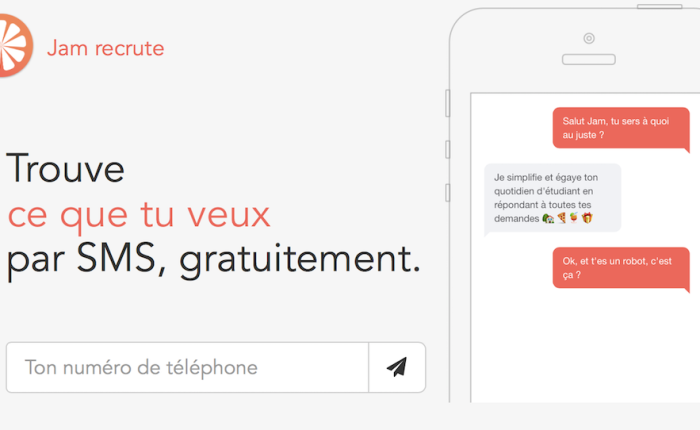
There is a third possibility for Paul to live serenely his student life: using a bot. I will introduce you JAM. This is the bot chat for French students. It is also their friend, their confidant and their advisor.
JAM,
The supervised artificial intelligence
that can provide answers to all of students’ questions
Jam is not a concierge service like Claque des doigts or a conversational commerce app like Magic and many others.
Jam is thought out to be the best friend of French students. Jam will help Paul for each step of his student life (housing, job, cultural outings…), motivate him at his examinations and remind him appointments. And all this for free … like a friend. Jam always find the info needed by Paul in minutes or hours if the need is complex. There is no commercial transaction with Jam.
A simple SMS to Jam, a message on Facebook Messenger or on @hellojam_ DM (Twitter) and the experience begins.

Jam works with an artificial intelligence supervised by humans. When Jam understands the nature of user need, it looks for the most appropriate information by connecting to existing APIs.



When the user’s message is not completely understood by AI, the bakers (name given by Jam for humans caring supervision), take over to meet the need. Using a classification brick, AI aids the work of bakers by classifying posts by categories and priority (e.g. information on hourly bus or train).
Launched in April 2015 by Marjolaine Grondin (CEO) and Loïc Delmaire (CTO), Jam knows since few months an explosive growth among students: from 3 000 to 25 000 users in just 4 months. In order to find the best answer to the needs of a student, Jam has over 40 partners such as Airbnb, BlaBlaCar, Uber, Deliveroo, Engie … and around sixty bakers.
In view of this undeniable success, the young French start-ups raised € 1 million from ISAI (investment fund of internet entrepreneurs) in January. This fundraiser has mainly to supplement the existing team with specialized profiles techs including Machine Learning, Data Science and NLP … to improve the automation of responses. Today, Jam receives about 30 000 messages per month and automatically treats about 30% of these messages. 50% of messages are processed in human-machine pairs and the remaining 20% are paid entirely by the bakers.
The repercussions in the press of the fundraiser was to significantly increase the number of users Jam. Therefore, the main challenge of the young Jam team for the coming months is to increase the quality and speed of service. information extraction, clustering, Natural Language Generation (NLG) are some obstacles to be overcome to achieve this next NLP!
Technological locks in Natural Language Processing for an usable chatbot
Understanding semantics to understand user
- Named Entity Recognition (NER) in general (addresses, persons, objects, dates, places, prices,…)
- Contextual informations processing (e.g. “What movies playing tomorrow night“, “Who is the doctor nearest to me?“)
- Messages clustering
- Coreferences processing
- Understanding multi-criteria needs (e.g. “I’m searching a 3 seat white sofa-bed“)
- Understanding degraded text (text-messaging language, spelling mistakes)
- Sentiment analyse to understand the user’s satisfaction
Dialogue manager
- Anticipation of the interaction with the user, establishment of conversational scenarios
- Detection of missing information to reduce interactions
Automatic generation of the response
- Varied Generation according to input data information given by user
- Simplified generation for some complex responses (e.g. reimbursement rate for a given care) or for some users with reduced cognitive abilities (e.g. mental disability, old age)
- Adjusted Generation according to the user’s satisfaction
- Emotional generation based on user personal problems (e.g. rape, theft, assault, breaking, suicide…)
Chat Bots, Conversational Apps, Invisible Apps, Platforms Bots…What business plan?
The year 2016 is the conversational app year. Indeed, before the announcement of Facebook M scheduled for April 2016, many startups are already positioned.
There are conversational apps focused on shopping (Assist, Kip, iAdvize…), travel organization (GoButler, Taylor), news (Quartz), health (Tess), DHR (Tara)…
Many verticals are affected by bot mania. These bots are intended to make life easier for users, but one of the criticisms we can make is that some bots (e.g. Prompt) allow only calibrated interaction as a command line.
It is not surprising to see these chatbots launched on app messaging (Telegram, Line, Facebook, …) or platforms (Kik, Slack, Skype …) to find you the perfect little summer dress, the cheapest flight to Rome or the typical restaurant in Lisbon. Manna is huge for publishers of these bots when their business model would be to take a commission on each sale made or to charge for brands wishing to launch their bot on these platforms.
Brands look favorably bots:
- First, chatbots are decidedly more customized to the user insofar as the information they refer adapt to the needs without having to change around the interface which is not the case for applications blinds. Finished the time spent to develop apps
- Second, messaging applications are now more users than social networks. The chatbot can increase the hearing and have a better understanding of customer needs involving more targeted sales.
However, the business around bots on messaging app and platforms must still be determined to become either a dynamic ecosystem or a slump bots. There are two possible perspectives. On the one hand, platforms like Facebook and Slack may decide to play on the verticals (health, travel, news …) such as Chinese WeChat.This gives them many benefits, services will be well integrated with specific language (eg @ to call the basketball game on Facebook Messenger) but this will limit innovation in the field because bots-human interactions will limited by a specific language determined by the platforms. Furthermore, dependence on a platform that can change the operating rules along the way as is the case today with the stores would flee developers in favor of more stable environments. On the other hand, bots as Jam, bots-free-for-all, would bring many innovations because they rely on the free expression of the user involving the development of a natural language understanding technology but there will be many challenges regarding quality of service.
For more information on JAM



CEO: marjolaine@hellojam.fr
CTO: loic@hellojam.fr
CPO: anas@hellojam.fr



































